



10G
10G Integrity: The DOCSIS® 4.0 Specification and Its New Authentication and Authorization Framework

One of the pillars of the 10G platform is security. Simplicity, integrity, confidentiality and availability are all different aspects of Cable’s 10G security platform. In this work, we want to talk about the integrity (authentication) enhancements, that have been developing for the next generation of DOCSIS® networks, and how they update the security profiles of cable broadband services.
DOCSIS (Data Over Cable Service Interface Specifications) defines how networks and devices are created to provide broadband for the cable industry and its customers. Specifically, DOCSIS comprises a set of technical documents that are at the core of the cable broadband services. CableLabs manufacturers for the cable industry, and cable broadband operators continuously collaborate to improve their efficiency, reliability and security.
With regards to security, DOCSIS networks have pioneered the use of public key cryptography on a mass scale – the DOCSIS Public Key Infrastructure (PKIs) are among the largest PKIs in the world with half billion active certificates issued and actively used every day around the world.
Following, we introduce a brief history of DOCSIS security and look into the limitations of the current authorization framework and subsequently provide a description of the security properties introduced with the new version of the authorization (and authentication) framework which addresses current limitations.
A Journey Through DOCSIS Security
The DOCSIS protocol, which is used in cable’s network to provide connectivity and services to users, has undergone a series of security-related updates in its latest version DOCSIS 4.0, to help meet the 10G platform requirements.
In the first DOCSIS 1.0 specification, the radio frequency (RF) interface included three security specifications: Security System, Removable Security Module and Baseline Privacy Interface. Combined, the Security System plus the Removable Security Module Specification became Full Security (FS).
Soon after the adoption of public key cryptography that occurred in the authorization process, the cable industry realized that a secure way to authenticate devices was needed; a DOCSIS PKI was established for DOCSIS 1.1-3.0 devices to provide cable modems with verifiable identities.
With the DOCSIS 3.0 specification, the major security feature was the ability to perform the authentication and encryption earlier in the device registration process, thus providing protection for important configuration and setup data (e.g., the configuration file for the CM or the DHCP traffic) that was otherwise not protected. The new feature was called Early Authorization and Encryption (EAE), it allows to start Baseline Privacy Interface Plus (BPI) even before the device is provisioned with IP connectivity.
The DOCSIS 3.1 specifications created a new Public Key Infrastructure *(PKI) to handle the authentication needs for the new class of devices. This new PKI introduced several improvements over the original PKI when it comes to cryptography – a newer set of algorithms and increased key sizes were the major changes over the legacy PKI. The same new PKI that is used today to secure DOCSIS 3.1 devices will also provide the certificates for the newer DOCSIS 4.0 ones.
The DOCSIS 4.0 version of the specification introduces, among the numerous innovations, an improved authentication framework (BPI Plus V2) that addresses the current limitations of BPI Plus and implements new security properties such as full algorithm agility, Perfect Forward Secrecy (PFS), Mutual Message Authentication (MMA or MA) and Downgrade Attacks Protection.
Baseline Privacy Plus V1 and Its Limitations
In DOCSIS 1.0-3.1 specifications, when Baseline Privacy Plus (BPI+ V1) is enabled, the CMTS directly authorizes a CM by providing it with an Authorization Key, which is then used to derive all the authorization and encryption key material. These secrets are then used to secure the communication between the CM and the CMTS. In this security model, the CMTS is assumed trusted and its identity is not validated.
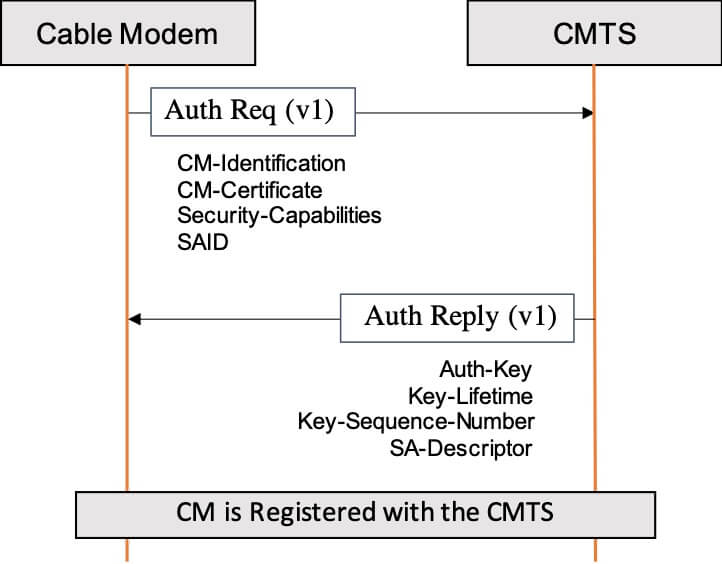
Figure 1: BPI Plus Authorization Exchange
The design of BPI+ V1 dates back more than just few years and in this period of time, the security and cryptography landscapes have drastically changed; especially in regards to cryptography. At the time when BPI+ was designed, the crypto community was set on the use of the RSA public key algorithm, while today, the use of elliptic-curve cryptography and ECDSA signing algorithm is predominant because of its efficiency, especially when RSA 3072 or larger keys are required.
A missing feature in BPI+ is the lack of authentication for the authorization messages. In particular, CMs and CMTS-es are not required to authenticate (i.e., sign) their own messages, making them vulnerable to unauthorized manipulation.
In recent years, there has been a lot of discussion around authentication and how to make sure that compromises of long-term credentials (e.g., the private key associated with an X.509 certificate) do not provide access to all the sessions from that user in the clear (i.e., enables the decryption of all recorded sessions by breaking a single key) – because BPI+ V1 directly encrypts the Authorization Key by using the RSA public key that is in the CM’s device certificate, it does not support Perfect Forward Secrecy.
To address these issues, the cable industry worked on a new version of its authorization protocol, namely BPI Plus Version 2. With this update, a protection mechanism was required to prevent downgrade attacks, where attackers to force the use of the older, and possibly weaker, version of the protocol. In order to address this possible issue, the DOCSIS community decided that a specific protection mechanism was needed and introduced the Trust On First Use (TOFU) mechanism to address it.
The New Baseline Privacy Plus V2
The DOCSIS 4.0 specification introduces a new version of the authentication framework, namely Baseline Privacy Plus Version 2, that addresses the limitations of BPI+ V1 by providing support for the identified new security needs. Following is a summary of the new security properties provided by BPI+ V2 and how they address the current limitations:
- Message Authentication. BPI+ V2 Authorization messages are fully authenticated. For CMs this means that they need to digitally sign the Authorization Requests messages, thus eliminating the possibility for an attacker to substitute the CM certificate with another one. For CMTS-es, BPI+ V2 requires them to authenticate their own Authorization Reply messages this change adds an explicit authentication step to the current authorization mechanism. While recognizing the need for deploying mutual message authentication, DOCSIS 4.0 specification allows for a transitioning period where devices are still allowed to use BPI+ V1. The main reason for this choice is related to the new requirements imposed on DOCSIS networks that are now required to procure and renew their DOCSIS credentials when enabling BPI+ V2 (Mutual Authentication).
- Perfect Forward Secrecy. Differently from BPI+ V1, the new authentication framework requires both parties to participate in the derivation of the Authorization Key from authenticated public parameters. In particular, the introduction of Message Authentication on both sides of the communication (i.e., the CM and the CMTS) enables BPI+ V2 to use the Elliptic-Curves Diffie-Hellman Ephemeral (ECDHE) algorithm instead of the CMTS directly generating and encrypting the key for the different CMs.Because of the authentication on the Authorization messages, the use of ECDHE is safe against MITM attacks.
- Algorithm Agility. As the advancement in classical and quantum computing provides users with incredible computational power at their fingertips, it also provides the same ever-increasing capabilities to malicious users. BPI+ V2 removes the protocol dependencies on specific public-key algorithms that are present in BPI+ V1. , By introducing the use of the standard CMS format for message authentication (i.e., signatures) combined with the use of ECDHE, DOCSIS 4.0 security protocol effectively decouples the public key algorithm used in the X.509 certificates from the key exchange algorithm. This enables the use of new public key algorithms when needed for security or operational needs.
- Downgrade Attacks Protection. A new Trust On First Use (TOFU) mechanism is introduced to provide protection against downgrade attacks – although the principles behind TOFU mechanisms are not new, its use to protect against downgrade attacks is. It leverages the security parameters used during a first successful authorization as a baseline for future ones, unless indicated otherwise. By establishing the minimum required version of the authentication protocol, DOCSIS 4.0 cable modems actively prevent unauthorized use of a weaker version of the DOCSIS authentication framework (BPI+). During the transitioning period for the adoption of the new version of the protocol, cable operators can allow “planned” downgrades – for example, when a node split occurs or when a faulty equipment is replaced and BPI+ V2 is not enabled there. In other words, a successfully validated CMTS can set, on the CM, the allowed minimum version (and other CM-CMTS binding parameters) to be used for subsequent authentications.
Future Work
In this work we provided a short history of DOCSIS security and reviewed the limitations of the current authorization framework. As CMTS functionality moves into the untrusted domain, these limitations could potentially be translated into security threats, especially in new distributed architectures like Remote PHY. Although in their final stage of approval, the proposed changes to the DOCSIS 4.0 are currently being addressed in the Security Working Group.
Member organizations and DOCSIS equipment vendors are always encouraged to participate in our DOCSIS working groups – if you qualify, please contact us and participate in our weekly DOCSIS 4.0 security meeting where these, and other security-related topics, are addressed.
If you are interested in discovering even more details about DOCSIS 4.0 and 10G security, please feel free to contact us to receive more in-depth and updated information.

Legal
The Personal and Social Implications of the End User License Agreement

As in-house counsel, I often read and write online licensing agreements for software. These agreements go by a variety of names, such as Terms of Service (ToS) or End User License Agreements (EULAs). These are the agreements you scroll through (without actually reading) and then click the “I Agree” box, thus legally binding yourself to something you didn’t take the time to read or understand in order to get something you want quickly.
Not Your Fault
Don’t feel bad about not reading EULAs. It would take a significant amount of time to read every one of the agreements you encounter. Also, many of them would require you to go to law school to understand them! And even if you didn’t like the terms of an agreement, your only options would be to try to negotiate better terms (best of luck with that!) or not use the software or service. Besides which, if you’re getting the software or service for free, you may ask, “Who cares?” You should! Even if the transaction doesn’t involve money, it isn’t actually free. You may not be giving up your money, but you are giving up your legal rights.
You may not care about some of those rights, as they often may not impact you too seriously. But one serious development I do see coming up more often is when a company reserves the right to change the agreement at any time by posting new terms on its website. If you continue to use that company’s software, then you automatically agree to the new terms. This means that it’s possible that a free app you downloaded one day wouldn’t be free the next day—and you wouldn’t know it unless you compulsively checked the website to read what you didn’t read the first time.
Sometimes You Can Win in Court – But You do Have to Go to Court
It’s not all bad in EULA land. In some instances, the court will have your back. Because EULAs are non-negotiable form agreements, they’re considered “adhesion contracts.” Generally, courts won’t allow the dominant party (the one that wrote the adhesion contract) to enforce an adhesion contract term if the court considers it “unconscionable”— that is, generally, and as a simplification, if the contract term is unfair to the weaker party. But that also means you have to sue and spend time paying for your case.
So Who is Going to Change the EULA?
Although there may be little incentive for lawyers to change EULAs on their own, there are incentives for the lawyer’s clients. Companies invest a lot in their customer experience. EULAs are clearly not part of that investment, but they should be—after all, the EULA is where the software or service is purchased. Companies are in a position to challenge their legal counsel to draft EULAs that work to enhance the customer experience. Outside of a sea change in the law, this may be the only way EULAs will change.
At Kyrio, I work hard to make our agreements as simple as possible. I have also launched my own initiative with lawyers and designers to develop contracts that are written in standard English. Subscribe to our blog to learn more in the future.

Legal
Do We Have Privacy Wrong?

Technology sparks changes in society, which brings changes in law, which can affect technology use and innovation. Privacy law in U.S. law provides a good demonstration of this technology, society, and law cycle. Recognition of a need for a right to privacy didn’t occur until December 15, 1890, when Samuel Warren and Louis Brandeis published “The Right to Privacy" in the Harvard Law Review. Warren and Brandeis felt a need to develop this new right because of the prevalence of a new technology: inexpensive cameras. Cameras, particularly in the hands of the press, allowed for “unauthorized circulation of portraits of private persons.” We now have laws that regulate how and where cameras are used.
Financial vs. Mental
The Internet has given rise to a new collection of privacy concerns that we have yet to resolve. The difficulty in resolving the non–4th Amendment (government intrusion) privacy issues that arise with technology may not be because of what the technology creates but how we view privacy. Current legal solutions—such as the California Consumer Privacy Act of 2018 (effective January 1, 2020), which in itself is based in part on the European General Data Protection Regulation which went into effect May 25, 2018,—focus on controlling data. This approach lumps together the financial harm that arises from identity theft with the mental harm that arises from privacy intrusion.
Confusing these two types of harm adds to the confusion that technology innovators may face regarding what data should be considered private. This, in turn, can negatively impact technical innovation as new innovations may create new types of data with uncertain legal implications. This negative impact could be lessened if intrusion-of-privacy concerns were decoupled from identity-theft concerns. That is, privacy should be less about data collection, storage and use and more about the tort of privacy intrusion. This is not to say that data protection isn’t important—particularly with regard to the financial impacts of identity theft—but rather that regulating data to limit privacy intrusion harm is akin to regulating how high someone can raise their arm while trying to protect against assault. (Assault, in a legal sense, is intentionally acting to cause the reasonable apprehension of an immediate harmful or offensive contact. This is different from battery, which is the harmful or offensive contact itself.)
A problem with regulating data as a means to protect against privacy intrusion is that it’s not always apparent that the data technology raises privacy implications. It isn’t likely that George Eastman considered the social impact of the Kodak camera’s ability to easily create and allow the sharing of a stranger’s image (“could he? should he?”). The many creators of the Internet couldn’t have reasonably foreseen what others might learn about us based on the apparently insignificant details of our Internet use scattered across the web, such as our IP address, websites visited, web pages visited, length of time spent on each web page, geographic location, what we post, and purchasing history—let alone the information we provide when we fill out forms.
Privacy Intrusion as Assault
Although the data you make available about yourself on the internet may not be apparent, what is apparent is what a privacy intrusion feels like to you. You feel vulnerable. To be vulnerable is to feel apprehension to mental harm, much as assault is the apprehension of physical harm.
Treating privacy intrusion like assault allows for the mental harm of privacy intrusion to be separated from the financial harm arising from identity theft. Separating these two types of harm results in more than just redress for the victims. It also allows the innovator to consider separately the identity theft and privacy intrusions that may arise in the implementation of the innovation rather than have to consider the legal implications in having identity theft and privacy intrusion lumped together. For example, online camera applications tend to have more privacy-intrusion risks whereas online payment applications tend to have more identity-theft risks. Clarity in the law helps the innovator identify the legal risks.
Renewed Focus
The cycle of technology impacting society, causing changes in the law, which then regulates technology is spinning faster than ever as a culture that favors innovation and disruption creates more technology faster than ever before. The right to privacy—one of the early U.S. legal creations to come from a new technology—is receiving a renewed focus. An intrusion of privacy, however, isn’t the same thing as identity theft. Lumping them together in the law helps neither the victim nor the innovator.
At CableLabs and Kyrio, we think about the social and legal impacts of innovation. We also create and bring to market technologies that enhance protections against identity theft and privacy intrusion.
Subscribe to our blog to learn more about law and innovation in the future.
Legal
Should Artificial Intelligence Practice Law?

As in many other professions, artificial intelligence (AI) has been making inroads into the legal profession. A service called Donotpay uses AI to defeat parking tickets and arrange flight refunds. Morgan Stanley reduced its legal staff and now uses AI to perform 360,000 hours of contract review in seconds and a number of legal services can conduct legal research (e.g., Ross Intelligence), perform contract analysis (e.g., Kira Systems, LawGeex, and help develop legal arguments in litigation (e.g., Case Text).
Many of these legal AI companies are just a few years old; clearly, there are more AI legal services to come. Current laws allow only humans that passed a bar exam to practice law. But if non-humans could practice law, should we have AI lawyers? The answer may depend on how we want our legal analysis performed.
AI Thinking
Today, when people talk about AI, they often refer to machine learning. Machine learning has been around for many years, but because it is computationally intensive, it has not been widely adopted until more recently. In years past, if you wanted a computer to perform an operation, you had to write the code that told the computer what to do step-by-step. If you wanted a computer to identify cat pictures, you had to code into the computer the visual elements that make up a cat, and the computer would match what it “saw” with those visual elements to identify a cat.
With machine learning, you provide the computer with a model that can learn what a cat looks like and then let the computer review millions of cat (and non-cat) pictures, stimulating the model when it correctly discerns a cat, and correcting it when it doesn’t properly identify a cat. Note that we have no idea how the computer structured the data it used in identifying a cat—just the results of the identification. The upshot is that the computer develops a probabilistic model of what a cat looks like, such as “if it has pointy ears, is furry, and has eyes that can penetrate your soul, there is a 95 percent chance that it is a cat.” And there is room for error. I’ve known people who fit that cat description. We all have.
Lawyer Thinking
If a lawyer applies legal reasoning to identifying cat pictures, that lawyer will become well versed in the legal requirements as to what pictorial elements (when taken together) make up a cat picture. The lawyer will then look at a proposed cat picture and review each of the elements in the picture as it relates to each of the legally cited elements that make up a cat and come up with a statement like, “Because the picture shows an entity with pointy ears, fur, and soul-penetrating eyes, this leads to the conclusion that this is a picture of a cat.”
In machine learning, the room for error does not lie in the probability of the correctness of the legally cited cat elements to the proposed cat picture. The room for error is in the lawyer’s interpretation of the cat elements as they relate to the proposed cat picture. This is because the lawyer is using a causal analysis to come to his or her conclusion—unlike AI, which uses probability. Law is causal. To win in a personal injury or contracts case, the plaintiff needs to show that a breach of duty or contractual performance caused damages.
For criminal cases, the prosecutor needs to demonstrate that a person with a certain mental intent took physical actions that caused a violation of law. Probability appears in the law only when it comes to picking the winner in a court case. In civil cases, the plaintiff wins with “a preponderance of the evidence” (51 percent or better). If it is a criminal case, the prosecution wins if the judge or jury is convinced “beyond a reasonable doubt” (roughly 98 percent or better). Unlike in machine learning, probability is used to determine the success of the causal reasoning, and is not used in place of causal reasoning.
Lawyer or Machine?
Whether a trial hinges on a causal or probabilistic analysis may seem like a philosophical exercise devoid of any practical impact. It’s not. A causal analysis looks at causation. A probabilistic analysis looks at correlation. Correlation does not equal causation. For example, just because there is a strong correlation between an increase in ice cream sales and an increase in murders doesn’t mean you should start cleaning out your freezer.
I don’t think we want legal analysis to change from causation to correlation, so until machine learning can manage a true causal analysis, I don’t think we want AI acting like lawyers. However, AI is still good at a lot of other things at Kyrio and CableLabs. Subscribe to our blog to learn more about what we are working on in the field of AI at CableLabs and Kyrio.
Legal
How Will the Law Treat Injuries Caused by Autonomous Vehicles?

A version of this article appeared in S&P Global Market Intelligence in April 2018.
Recently, in Arizona, a self-driving Uber vehicle with a minder onboard struck and killed a cyclist. The deadly accident has raised familiar—and serious—philosophical and legal questions surrounding the rise of autonomous vehicles.
There’s an important philosophical debate already being waged over self-driving cars and safety in the wake of this tragedy, but the fact that I’d have to look up the meanings of “deontological” and “teleological” disqualifies me for that discussion. However, I am a practicing lawyer, and although I don’t practice personal injury law, I do have sufficient bona fides to opine on tort law and autonomous vehicles.
Tort Law
Culpability in the Arizona crash will be legally decided in accordance with the principles of tort law. A tort is, simply, a civil wrong - that is a wrongful act causing harm to a member of society. This is not to be confused with a criminal act, which requires a mental state and action that causes a violation of a criminal law. Torts require four elements, and all four elements must be met, or you don’t have a case:
- A civic duty
- A breach of that civic duty
- The breach of the civic duty led directly to a harm
- The harm resulted in damages
Using the framework of tort law, in the event that an autonomous vehicle causes an accident, it is the first two elements of a tort—there was a duty, and that duty was breached—that are significant. In this case, there may be several legal duties.
Uber and Autonomous Vehicle
One legal duty could be found with Uber or the car manufacturer (by “manufacturer,” I mean the designer, software provider, and everyone else in the supply chain). Uber and the manufacturer have a legal duty to not design or manufacture a defective product. The question here is whether the Uber self-driving car involved in the accident was defectively designed or manufactured, and whether it was Uber or the car manufacturer that put a defective vehicle on the road.
What makes a self-driving car defective? Answers to that question will be based on the “standard of care.” Reviewing the standard of care means understanding what a reasonable car manufacturer and self-driving car modifier would do for safety. Lawyers will review what other self-driving car companies, such as Waymo, have done with regard to numbers and types of sensors, as well as bring in self-driving car experts. More standard questions as to the effectiveness of the car’s brakes may also come into play.
The Minder
There are also legal duty questions about the Uber employee who was in the vehicle and who was allegedly not looking at the road at the time of the accident. I would assume the minder was in the car to help prevent accidents. If that’s the case, she probably had a legal duty. However, what if she had been in the car for a sufficient amount of time to reasonably become fatigued and had no way of pulling over? Driving long hours is hard enough. Being a passenger—not controlling the car but needing to keep a sharp eye on a road—seems like a monotonous job.
If Uber had the minder in the car too long to be effective, that may be a design defect. On the other hand, if the employee could have pulled the car over to rest, then she may have breached her duty. Going one step further, does Uber or the car manufacturer have a duty to put in a sensor that would detect when the minder became fatigued and instruct the car to automatically pull over?
The Cyclist
The fault is not all on the car manufacturer and Uber. The woman who was killed was crossing a well-trafficked road at night pushing a bicycle. Did she breach a legal duty? If so, and if the court finds that the car manufacturer or Uber breached its legal duty, then it is a case of comparative negligence and the court may reduce the car manufacturer’s or Uber’s damages in accordance with the amount of negligence of the woman who was killed.
Arizona is a comparative negligence state, which means someone can recover damages under tort even if he or she were 99 percent at fault (compared with Maryland, which is a contributory negligence state, where the plaintiff gets nothing even if he or she is 1 percent at fault). Under Arizona law, however, there won’t be any recovery if the deceased intentionally caused the accident—so that raises the question of intent.
More to Come
While the Uber case reached an undisclosed settlement it would be overly optimistic to think that this accident will be the last accident involving a self-driving car. While it’s too early to tell how these self-driving car cases will play out in the courts, this is one area of the law that may not need to struggle to keep up with changes in technology (such as privacy law). Traditional tort law provides a legal framework for deciding fault and damages for self-driving cars.
The crossroads of law, technology and society is an interesting place to be. This article is the first part of our legal series by our legal experts at CableLabs examining the impact of new technologies on law and how we live. Make sure to subscribe to our blog to stay current on our legal series.
--
Yes, I am an attorney, but I’m not your attorney and this article does not create an attorney-client relationship. I am licensed to practice law in Colorado and have based the information presented on US laws. This article is legal information and should not be seen as legal advice. You should consult with an attorney before you rely on this information.
Education
Security Infrastructure Enhances Student Privacy, Data Protection, and Can Make Life Easier


In the days of typewriters and post offices, students knew that their educational data, everything in that mysterious file ominously referred to as “your permanent record,” could only be read if someone went into a school’s file room or someone made a copy and mailed it to someone else. For a long time, there were no state and federal laws that read directly on student academic privacy. Eventually, both state and federal laws were enacted which provided increased and detailed protections. While these laws protect each student’s data, complying with the details of each federal and state privacy law can result in a legal minefield for those that need to access a student’s data. As student privacy rules and regulations become more complex, there is an increasing need to leverage a more modern approach to privacy controls and data security. Such an approach would enable automation of regulatory compliance as well as increased protections for student records.
The Legal Landscape
Student privacy laws began with the federal Family Education Rights and Privacy Act (FERPA) in 1974. Additional state and federal laws have added restrictions and complexity to the safeguarding of student records. These laws have followed the arc of the internet and now often include provisions that arise out of schools using online services such as a focus on parental notification and consent when student data is released to third parties. In the U.S., issues such as how data is collected and how it will be used have become hotly debated topics among parent advocates, school administrators, online service providers, and legislatures.
Digital Tools to Manage Academic Privacy Requirements
While the intention of each federal and state student privacy law is good, it is easy to see how all of the laws, taken together, can lead to confusion as to who is to be allowed access to what student data, when is access allowed, and when parental consent is necessary. There is the additional demand that the schools provide sufficient data security. This regulatory complexity paired with the need for sufficient data security can stretch resources for school officials. In addition, the fragmented nature of regulation may stifle any company or institutional innovation due to uncertainty as to what may be legally permissible.
A possible solution lies in automating compliance with privacy requirements through the adoption of modern cryptography techniques that inherently limit access. This approach provides more refined access control beyond ensuring that only the educational institution’s faculty and staff have access to student records. Additionally, cryptography will make school records much more difficult to hack, thereby protecting the integrity of the records and the privacy of the student (such as: grade tampering at the University of Iowa reported on 1/23/17 and extortion hacking at Michigan State).
For example, with the appropriate digital security in place, a high school senior may electronically authorize a school to permit certain universities to receive the student’s academic record. Using security such as a Public Key Infrastructure (PKI), the high school may transmit an encrypted student’s academic transcript to the universities that the student has authorized to receive those records and only those universities would have the necessary key to decrypt the record. PKI also authenticates the student and the transcript. Because the student’s electronic record is encoded with the appropriate legal access controls, only the student’s academic transcript is sent. Other records, such as household income or medical records, are not transmitted. Similarly, in the event a health care provider needs a student’s medical records, the appropriate digital security would ensure that only the student’s medical records are sent. More granular security controls also mean that student data can be de-identified and aggregated to enable researchers and third parties working with educators to improve the educational process.
CableLabs and Kyrio’s research and experience managing digital security for cable, wireless, and the electrical grid have demonstrated the value in using cryptographic access control. Using cryptography to automate privacy controls through a digital security infrastructure means less legal confusion for administrators, enhanced privacy and data security for students, and room for greater educational innovation. Additional benefits can occur by adding blockchain technology in addition to cryptography, topics addressed in these previously published blogs.
Blockchains and the Cable Industry
Hello Blockchain . . . Goodbye Lawyers?
By Simon Krauss, Deputy General Counsel, CableLabs
Consumer
Hello Blockchain . . . Goodbye Lawyers?


As the blockchain technology star begins to eclipse Bitcoin and the other cryptocurrencies that rely upon it, there has been an increase in research and development into using blockchain for “smart contracts.” Smart contracts are computer programs that facilitate, verify, execute, and enforce a contract. While smart contracts have existed to a limited extent for years in the commodities markets, vending machine, or adjustable rate mortgage industries, blockchain technology enables smart contracts to expand to cover new uses and, ultimately, become mainstream because contracts in blockchains are attestable, immutable, and visible.
What is a Contract? What is Blockchain?
A contract, in its simplest terms, is an agreement between people to do or refrain from doing something in exchange for something else. The agreement, generally, can be formed through a mutually signed document, a series of emails, verbal communication, clicking “I Agree” or any action showing agreement. A contract may be formed by the simple nodding of the head. A “person” can be a human being or an entity created in law with the ability to contract, like a corporation or a limited liability company. In order for an agreement to be upheld legally, the agreement cannot be against the law. Yet another reason why you don’t see drug dealers in court -- criminal court excepted.
Blockchain is a cryptographic technology that is used to create distributed, verifiable electronic ledgers to record events. For more elaboration refer to Steve Goeringer’s post. Smart contracts leverage blockchain technology to not only record the individuals and the amounts in the transaction but can also set up a self-executing “if this than that” structure using scripts.
A Smart Contract in Action
For example, if you and I were to agree upon a price for you to buy my car, we would both be worried about certain risks. I would be afraid whether or not your check will clear. You would be concerned if I actually hold a clear title to the car, whether the car is mechanically sound, if there are any liens on the car, and would want to confirm the odometer reading is accurately stated on the title. Addressing these concerns may take a week or more. With a blockchain, all the concerns are addressed simultaneously.
For this example, let’s assume we are living in the near future and the title (VIN number, ownership and odometer reading – the latter due to my car phoning in to update its secured record), and any liens are encoded on the blockchain, the payment will be in Bitcoin (or some other cryptocurrency), and my contract with the mechanic can also be on the blockchain. I would load the coded representation of our agreement onto the blockchain. The blockchain would immediately determine if you had the funds, I had the proper title, check for the “this car is okay” approval from the mechanic, check (and pay off) any liens and then, if all the conditions are present, transfer your payment to me, and transfer and record the title on the blockchain. We receive the mutual “okay” on our smart phones and I give you the car key. The sale of the car becomes spontaneous. So long as the cryptography is sound, there is no longer the need for trust. That is, I would not have to trust you to have the funds to purchase the car and you would not have to trust that I actually had title to the car, the car was mechanically sound, there were no liens on the car, and the odometer reading is correct.
Smart Contracts in the Cable Industry
Smart contracts can remove friction and provide transparency in the cable supply chain. For example, smart contracts could ensure that every time a cable operator shows a movie, appropriate payments are instantaneously made all the way down the programming supply chain. There is no need for audit as the transaction history is readily secured and apparent in the blockchain. Smart contracts could also reduce costs by streamlining content purchasing based upon industry standards. Smart contracts could also be readily applied to advertising insertion with payment made in real time.
So We Don’t Need Lawyers Anymore?
For certain simple transactions, for which you probably wouldn’t hire a lawyer, you still wouldn’t need a lawyer. However, the use of blockchain may reduce the need for a using a lawyer to resolve post-contract issues like lack of payment or, in the previous example, bad title. Smart contracts may reduce the need for litigators but become an additional tool for the transactional lawyer to master. The question may be better phrased as, “do lawyers need to learn coding along with Latin?” or “do coders need law degrees?” or even, “is coding a new role for paralegals?” Written contracts are legal documents and while you are free to draft your own, drafting for others constitutes practicing law without a license – which is against the law. While smart contracts will undoubtedly impact lawyers and the practice of law, smart contracts will not eliminate the need for lawyers right away. Smart contracts may, however, be one of several technologies that will bring us one step closer to eliminating or reducing the need for lawyers in the future.