



Technology Vision
Network Comprehension: Teaching AI to Monitor Your Network Traffic

Key Points
- An automated method for understanding network communications would allow better visibility into network issues, allow users to troubleshoot and fix their own network problems, and greatly reduce customer service costs.
- Existing cloud solutions have privacy concerns, use unnecessary bandwidth, and require a functioning backhaul. The CableLabs solution is completely local and can run on customer premises equipment (CPE).
- The model has built-in flexibility for easy retraining for new use cases.
In November 2024, CableLabs released NetLLM: Your Handy Automated Network Assistant. NetLLM is a set of tools that collects metrics from the network and passes them as text to an out-of-the-box Large Language Model (LLM) trained on natural language for analysis. This approach works well and has the added benefit of allowing people to communicate with their router in conversational English.
The next step, which is the subject of this blog post, was to train a model on network communication itself rather than a text description. Our model is trained on the raw network packets, treating the sequence of packets as a language by handling each packet as a sentence in the context of the overall network conversation. This approach led to a custom architecture that allows us to build a real intuition for understanding network traffic in more detail.
What We Made
Our model takes in a Packet CAPture (PCAP) and outputs its understanding of what’s happening in that network traffic in the form of a vector of numbers (or embedding) for each packet. In LLMs, words and ideas are internally represented using embeddings, which are tuned to reflect the ideas they represent. If you think of packets as their own ideas, then you can represent these ideas numerically too, with embeddings, which can be thought of as translations of packets on the network to something that a machine can understand.
As a test, we used these embeddings to classify traffic into categories, focusing on two initial use cases: identifying the type of IoT devices on a network and detecting security attacks. For each of these use cases, the embeddings were transformed to create a probability distribution for the target classes, which allowed us to classify the traffic into two or more categories (or labels). Our categorization success rate with each of these use cases was over 90%.
Architecture Overview
To capture the full meaning of a PCAP, the most important aspects are the timing and content of each packet and the relationship between packets; the architecture needs to reflect this.
The first step is to break each packet down into its constituent protocols, each of which is passed through a dedicated layer that has learned to extract features specific to that protocol. The packets are then sent through a Long Short-Term Memory (LSTM) network, which is a type of machine learning layer that excels at extracting temporal relationships between time steps and transforming them to take previous time steps into account. We then pass these time-aware representations through a self-attention layer that excels at identifying the role and meaning of each packet in the broader context of the surrounding packets.
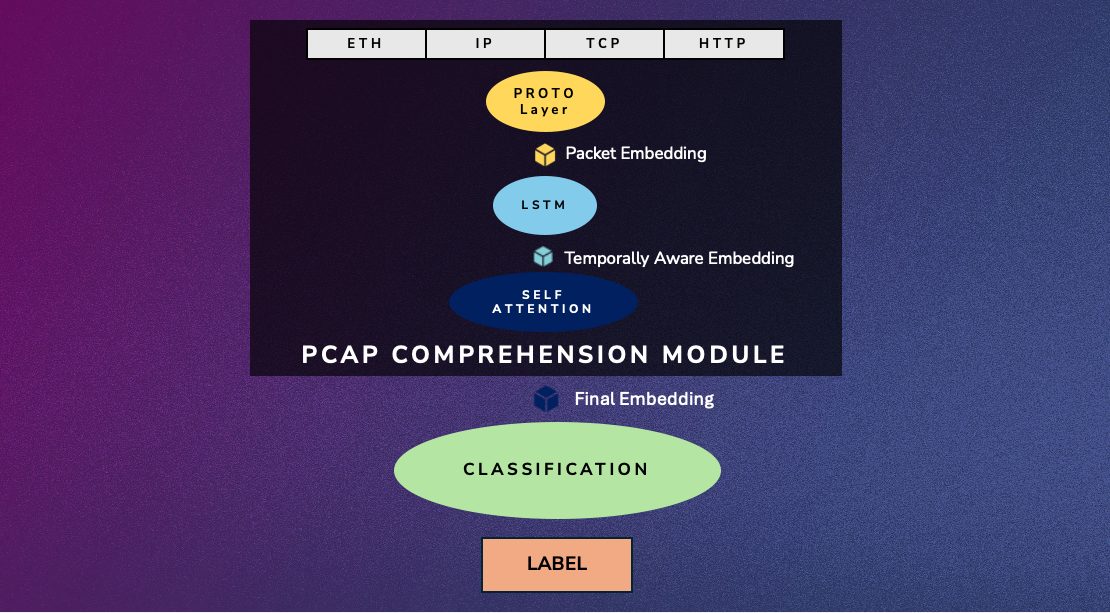
Figure 1: A high-level overview of the path that a packet takes as it is processed by our model and what it represents at each step
The output of the model, the final embedding, is a list of embeddings, one per packet, that is a learned understanding of the original PCAP. To see how you can use these embeddings, imagine a classification task. These embeddings would be used to predict which class a given PCAP belongs to. For example, if we trained the model to predict which type of IoT device we’re looking at, the output of this classification would be a probability distribution over the potential labels (e.g., 80% smart camera, 10% smart lightbulb, and 10% other).
When designing our architecture, we wanted to make sure that our model could exist where it would be most effective. Many network analysis tools are quite large and live in the cloud, which has a few potential drawbacks:
- There are privacy concerns in sending potentially confidential information up to the cloud.
- Sending all traffic up to the cloud is a huge waste of upstream bandwidth.
- The analysis system fails if the backhaul goes down and the cloud cannot be reached.
We focused on a local solution, making the model as lightweight as possible, so that it could run on CPE and function even without access to the wider internet.
Continued Development
But there is more that can be done with these embeddings!
The Packet Transformer. When we take a wider view of the PCAP Comprehension Module in Figure 1 above, it looks similar to the encoder block of a transformer. For natural language processing (NLP) classification tasks, in models like BERT, the encoder is used to understand and then classify the input, just like our model. To produce text, most modern LLMs use a decoder-only architecture. This works well for text because text doesn’t need any additional processing or understanding. So, if we feed our embeddings into the decoder (along with text and any other relevant measurements), we would be able to create a Multi-Modal LLM that has a deep understanding of network communications and can explain and answer questions about it.
The Network Agent. This PCAP Comprehension module could also be used as a network comprehension agent inside a larger agentic system. In this way, the comprehension agent would be invoked when the coordinating agent thinks there is a need to look in detail at network traffic.
Building for the Future
As our industry moves forward, flexible and resilient systems that can communicate better with consumers are a necessity. Systems that both understand networking and diagnose/fix issues can solve customers’ problems more quickly and save on customer service costs.
This innovative approach is powerful, lightweight and able to run directly on CPE. So, instead of trying to squeeze as much compute power into hardware as possible (which is expensive, power-hungry and time-consuming), we can work smarter by using this novel architecture on any existing hardware.
To continue to develop our model, we need more data. If you are a CableLabs member or part of our vendor community, this is where you can help. If you have any labeled or unlabeled PCAPs and would like to contribute to this model development or collaborate, let us know.